|
I am a research scientist at Roblox. My research focuses on 3D content creation. I obtained my Ph.D. in 2025 from Carnegie Mellon University, where I was fortunate to be co-advised by Deva Ramanan and Jun-Yan Zhu. My Ph.D. research was supported by Microsoft Research Ph.D. Fellowship. Prior to joining CMU, I obtained my B.S. in 2020 from Peking University. |

|
|
|
|
Ava Pun*, Kangle Deng*, Ruixuan Liu*, Deva Ramanan, Changliu Liu, Jun-Yan Zhu ICCV, 2025 (Best Paper Award, Marr Prize) project page / github / demo BrickGPT generates a physically stable and buildable brick structure from a user-provided text prompt in an end-to-end manner. |
|
|
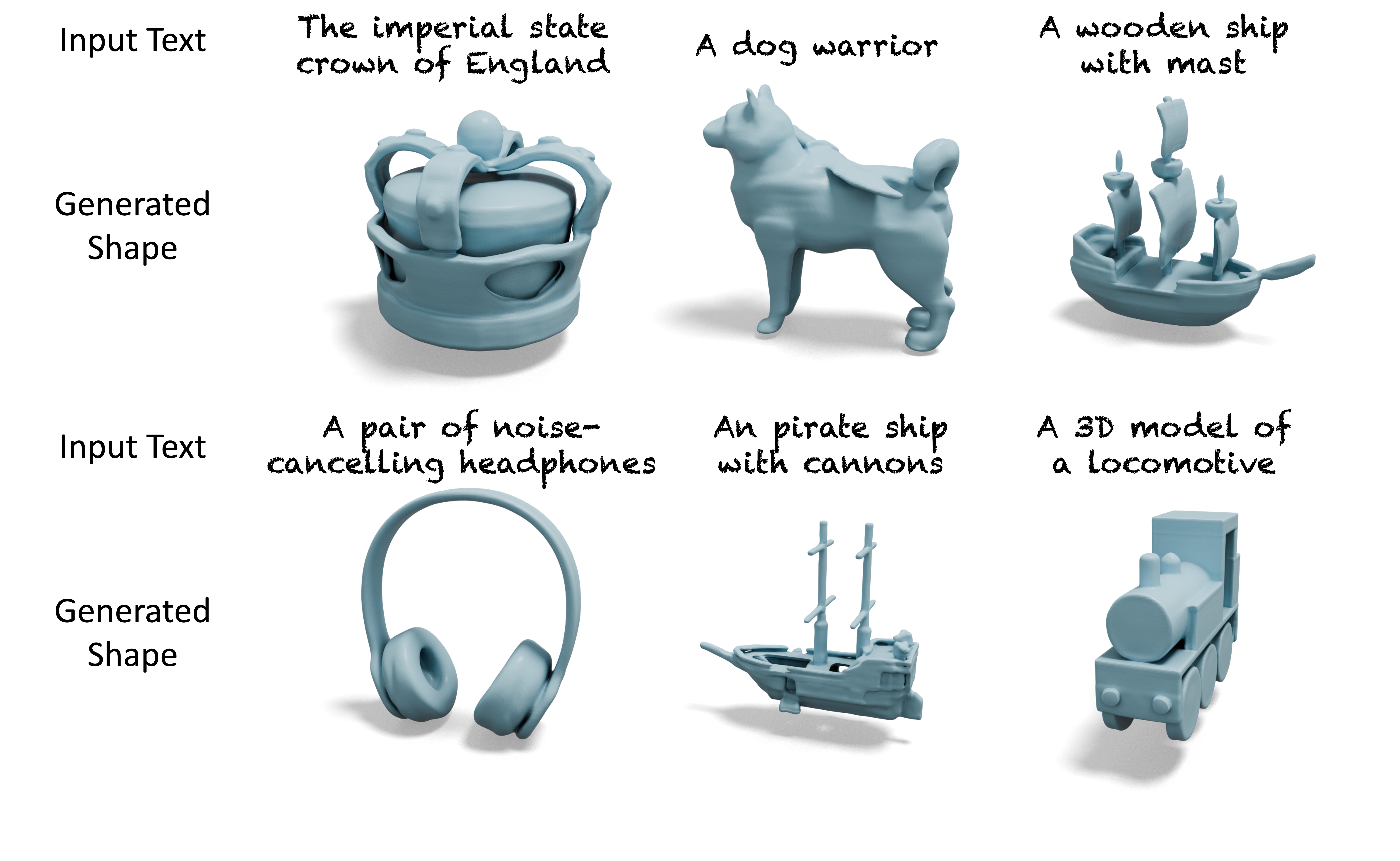
Kangle Deng, Hsueh-Ti Derek Liu, Yiheng Zhu, Xiaoxia Sun, Chong Shang, Kiran Bhat, Deva Ramanan, Jun-Yan Zhu, Maneesh Agrawala, Tinghui Zhou ICCV, 2025 project page Octree-based Adaptive shape Tokenization (OAT) dynamically allocates tokens based on shape complexity, achieving better quality with fewer tokens on average. |
|
Foundation AI Team (Kangle Deng: core contributor), Roblox Technical Report, 2025 blog / github First step towards building a foundation model for 3D intelligence that can support developers in producing all aspects of a Roblox experience, from generating 3D objects and scenes to rigging characters for animation to producing programmatic scripts describing object behaviors. |
|
|
Yehonathan Litman, Or Patashnik, Kangle Deng, Aviral Agrawal, Rushikesh Zawar, Fernando De la Torre, Shubham Tulsiani 3DV, 2025 project page / github Distill a material diffusion prior model into material parameters during inverse rendering to improve intrinsic decomposition and novel relighting. |
|
|
Ruihan Gao, Kangle Deng, Gengshan Yang, Wenzhen Yuan, Jun-Yan Zhu NeurIPS, 2024 project page / github 3D content creation with touch: TactileDreamFusion exploits high-resolution tactile sensing to enhance geometric details for text- or image-to-3D generation. |
|
|
Kangle Deng, Timothy Omernick, Alexander Weiss, Deva Ramanan, Jun-Yan Zhu, Tinghui Zhou, Maneesh Agrawala ECCV, 2024 (Oral Presentation) project page / github FlashTex textures an input 3D mesh given a user-provided text prompt. Notably, our generated texture can be relit properly in different lighting environments. |
|

|
Ruixuan Liu, Kangle Deng, Ziwei Wang, Changliu Liu IEEE Robotics and Automation Letters (RA-L), 2024 github We propose a new optimization formulation to infer the structural stability of block stacking assembly. We also provide StableLego: a comprehensive Lego assembly dataset of more than 50k Lego structures with their stability inferences. |
|
Chonghyuk(Andrew) Song, Gengshan Yang, Kangle Deng, Jun-Yan Zhu, Deva Ramanan ICCV, 2023 project page / github Given a RGBD video of deformable objects, Total-Recon builds 3D models of objects and background, which enables embodied view synthesis. |
|
|
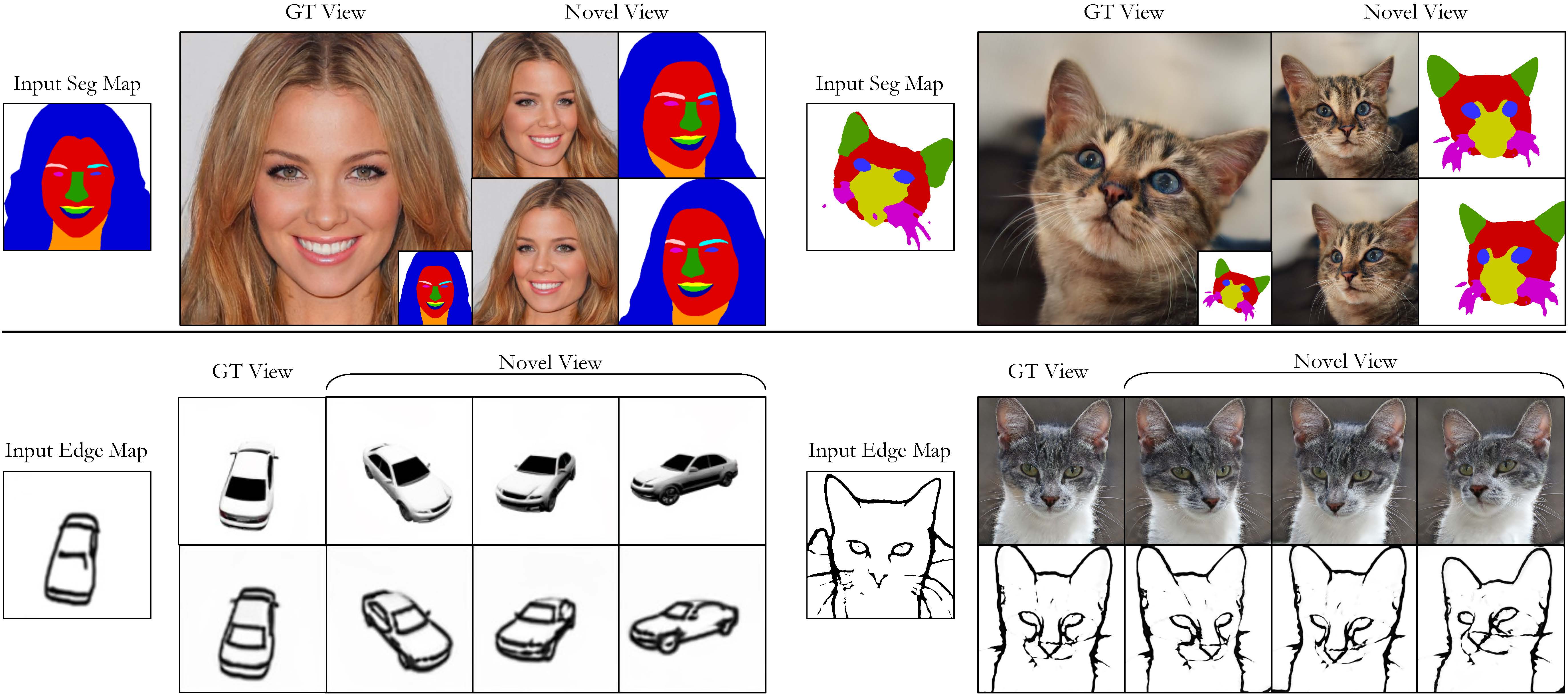
Kangle Deng, Gengshan Yang, Deva Ramanan, Jun-Yan Zhu CVPR, 2023 project page / github We propose pix2pix3D, a 3D-aware conditional generative model for controllable photorealistic image synthesis. Given a 2D label map, such as a segmentation or edge map, our model learns to synthesize a corresponding image from different viewpoints. |

|
Kangle Deng, Andrew Liu, Jun-Yan Zhu, Deva Ramanan CVPR, 2022 project page / github Proposed DS-NeRF (Depth-supervised Neural Radiance Fields), a model for learning neural radiance fields that takes advantage of depth supervised by 3D point clouds. |
|
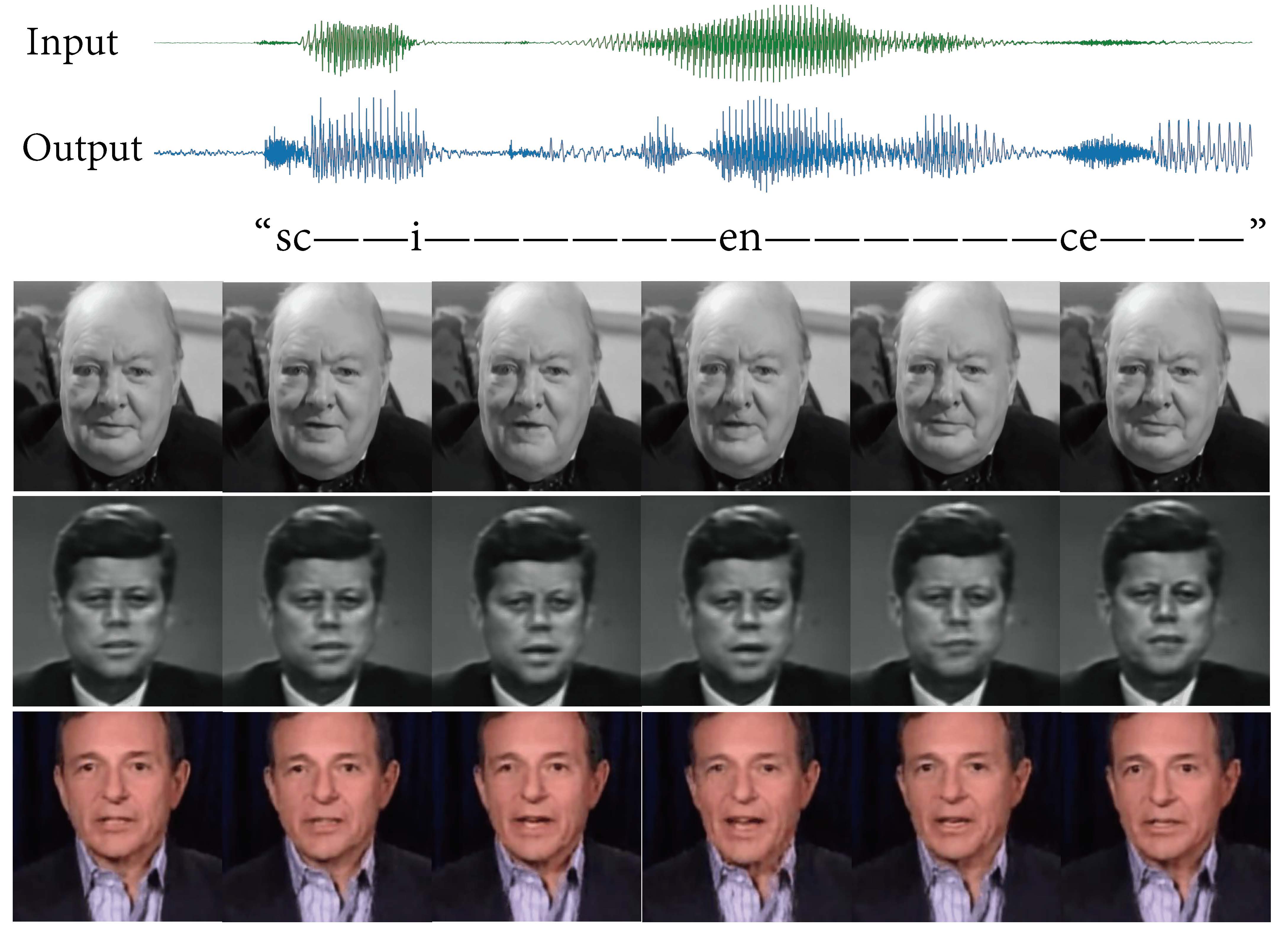
Kangle Deng, Aayush Bansal, Deva Ramanan ICLR, 2021 project page Defined and addressed a new question of unsupervised audiovisual synthesis -- input the audio of a random individual and then output the talking-head video with audio in the style of another target speaker. |

|
Kangle Deng*, Tianyi Fei*, Xin Huang, Yuxin Peng IJCAI, 2019 bibtex Application of Mutual Information to Text-to-video Generation. |
|
|
Teaching Assistant:
|
|
This webpage is "stolen" from Jon Barron. Thanks to him! |